
EXCELファイルをドキュメントDBへ格納するところまで進めてきました。
今回は、ドキュメントDBからリレーショナルDBへと格納していきます。前回、前々回、参照したシーケンス図に、更に E/T/L のシーケンスを追加しています。
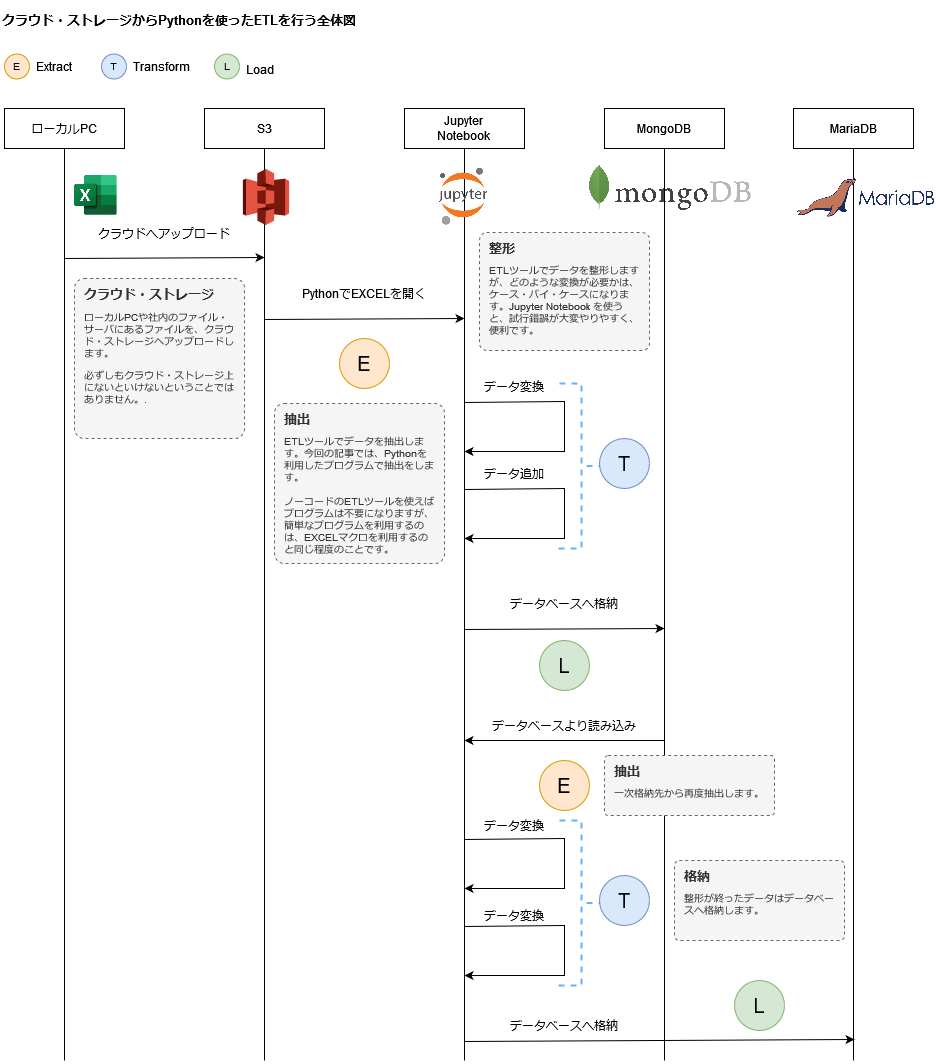
このように、ETLは段階を経て行うこともあります。システムの要件、業務の要件は、様々で、一度の処理で全ての要求を満たすことは難しいことも少なくありません。複雑な要求を仕様にまとめるために、データ分析のプラットフォーム構築が遅れることも、速度を求められるビジネスの中では望ましいことではありません。
あくまでデータに即して、データをいち早くユーザの手元に届けられるように、段階を踏んで処理をすることで、
- 途中経過もデータとして残すことが出来る。途中経過のデータも二次利用、三次利用を検討することが出来る。
- 完全ではなくても経過をアウトプットすることで、ユーザの意見を聞くことが出来る。
といったメリットもあります。
「データの民主化」ということを、データ・マネジメントの中では言いますが、民主化というのは様々なプロセスと様々なステージを踏んで勝ち取ることが出来るものだと思います。答えは一つではありません。一歩一歩、出来ることを進めるのが、重要です。
それでは、リレーショナルDBへのデータの格納をみていきます。
本記事の1回目を読んでいただけた方には、実はこの過程がとても簡単であることはご紹介済みです。
ドキュメントDBからリレーショナルDBへデータを格納する
業務経歴書を例にETLの実例を紹介していますが、ドキュメントDBへJSON形式でデータを格納したところまでが前回でした。
これをリレーショナルDBへ持っていきましょう、という話ですが、どういう戦略にするかを検討します。
まず、このデータはどういう構造だったかを再度確認しますと、単純ですがこのようなデータでした:
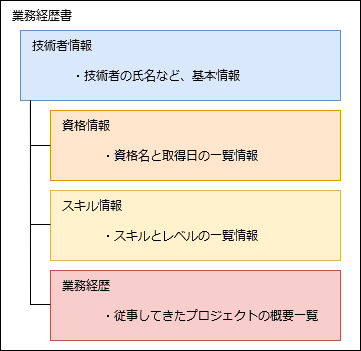
技術者情報は、氏名や生年月日などの基本情報になります。
その情報に紐づいて、
- 資格
- スキル
- 業務経歴
がそれぞれ記載されている、ツリー上のデータ構造になっています。
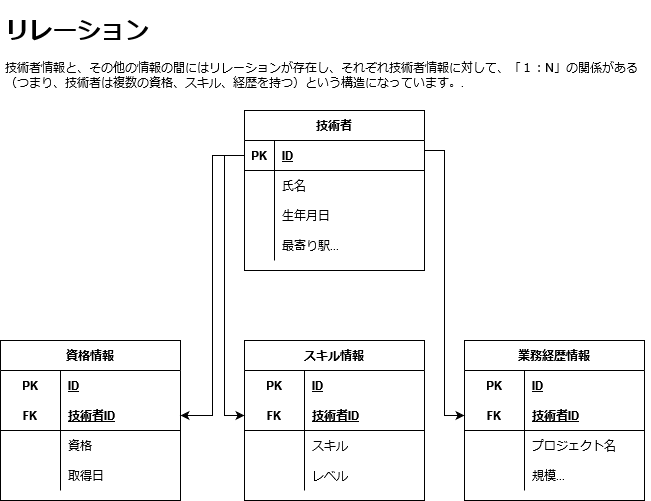
一方で、リレーショナルDBというのは1つのデータでツリー構造を表すことが出来ません。あくまでも1つのデータは表形式です。その表形式のデータの間の、「関係=リレーション」を表現することが出来る、というのが、リレーショナルDBの大きな特徴です。
リレーショナルDBのイメージは、下図のようになっています。技術者の下に、それぞれの情報が関係していて、1:Nの関係にある、と言います。
このように、「技術者」情報と、それに関係する情報を分けて管理することを、「正規化する」と呼びます。データの適切な正規化によって、リレーショナルDBは非常に強力なデータ・プラットフォームになります。
しかし、ここでは、一旦「正規化」は考えません。
冒頭で説明したとおり、あるべき姿を求めるのは大切ですが、簡単で素早く実装出来る方法を繰り返していくのも、重要な戦略です。
ここでは、ETLを素早く実装することのみ考えます。
データの冗長化を許容し、簡単にリレーショナルDBへデータを格納する
または、単純に、
オブジェクトDBからリレーショナルDBへ、右から左に移し替える
こととします。
再度図示すると、下図のようなイメージです。
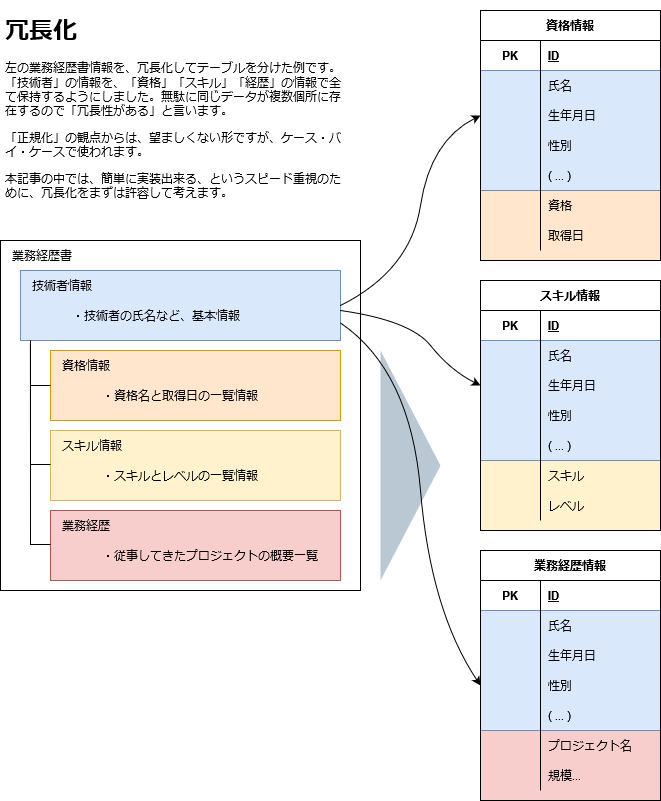
技術者は、氏名、生年月日、性別、の3つの項目で、個人を特定できる限りにおいて、後からまとめることが出来ます。同姓同名かつ同一生年月日の場合や、どれか一つでも情報がかけている場合など、実際には課題が残りますが、細かいことは今回は省いて説明します。
実装例
では実装例です。
まず、3つのデータをそれぞれ取り出すところです。ループしながらデータをためていきます。
import pandas as pd
# MongoDB へ接続
from pymongo import MongoClient
import pymongo
# 接続文字列
CONNECTION_STRING = "mongodb://mongo.minamirnd.work:27017/?ssl=true"
# Create a connection using MongoClient. You can import MongoClient or use pymongo.MongoClient
from pymongo import MongoClient
engineer = []
certificates = []
experiences = []
with MongoClient(CONNECTION_STRING) as client:
# データベースからデータを取り出す。
database = client['testdb']
collection = database['resumes']
# metadata.status が 'exported' ではないものをすべてのデータを対象とする
for data in collection.find({'metadta.status': { '$ne': 'exported'}}):
eng = {}
eng['name'] = data['氏名']
eng['kana'] = data['よみかな']
eng['gender'] = data['性別']
eng['birth_date'] = data['生年月日']
eng['station'] = data['最寄り駅']
eng['introduction'] = data['自己紹介']
eng['objectives'] = data['方向性']
engineer.append(eng)
for cert in data['資格']:
cert_info = {}
cert_info['name'] = data['氏名']
cert_info['kana'] = data['よみかな']
cert_info['gender'] = data['性別']
cert_info['birth_date'] = data['生年月日']
cert_info['station'] = data['最寄り駅']
cert_info['introduction'] = data['自己紹介']
cert_info['objectives'] = data['方向性']
cert_info.update(cert)
certificates.append(cert_info)
for experience in data['業務経歴']:
exp_info = {}
exp_info['name'] = data['氏名']
exp_info['kana'] = data['よみかな']
exp_info['gender'] = data['性別']
exp_info['birth_date'] = data['生年月日']
exp_info['station'] = data['最寄り駅']
exp_info['introduction'] = data['自己紹介']
exp_info['objectives'] = data['方向性']
exp_info.update(experience)
experiences.append(exp_info)
# 技術者情報、資格情報、スキル情報、経歴情報、の4つを「データフレーム」として作成する
engineer_df = pd.DataFrame(engineer)
certificates_df = pd.DataFrame(certificates)
experiences_df = pd.DataFrame(experiences)
技術者情報を、それぞれのデータに冗長化させているのが、
cert_info[‘name’] = data[‘氏名’]
cert_info[‘kana’] = data[‘よみかな’]
cert_info[‘gender’] = data[‘性別’]
cert_info[‘birth_date’] = data[‘生年月日’]
cert_info[‘station’] = data[‘最寄り駅’]
cert_info[‘introduction’] = data[‘自己紹介’]
cert_info[‘objectives’] = data[‘方向性’]
の部分です。技術者情報を保持した上で
cert_info.update(cert)
というように「update」というメソッドを利用して、ここでは資格情報も追記して、一覧データなので
certificates.append(cert_info)
として、リストに追加しています。同じことを、スキル、経歴、についても行っています。
これで、「技術者情報」「資格情報」「スキル情報」「経歴情報」の4つが出来ました。
データフレームをリレーショナルDBへ格納する
この処理は1回目でも行いました。Pythonのデータフレームというデータは、そのままデータベースに格納することが出来ます。
from sqlalchemy import create_engine
# データベースへの接続情報
hostname="★★データベースのホスト名★★"
dbname="★★データベース名★★"
uname="★★ユーザ名★★"
pwd="★★パスワード★★"
# 接続文字列を組み立てる。.format を使って、プレースホルダの変数へ値を代入している
engine = create_engine("mysql+pymysql://{user}:{pw}@{host}/{db}".format(host=hostname, db=dbname, user=uname, pw=pwd))
# テーブル名を指定して、SQLを発行する
# 既存のテーブルならば追加でINSERTをする
# テーブルが存在しなければ、新しくテーブルを作成する(if_exists='append')
engineer_df.to_sql('resumes_engineer', engine, index=True, if_exists='append')
certificates_df.to_sql('resumes_certificates', engine, index=True, if_exists='append')
skills_df.to_sql('resumes_skills', engine, index=True, if_exists='append')
experiences_df.to_sql('resumes_experiences', engine, index=True, if_exists='append')
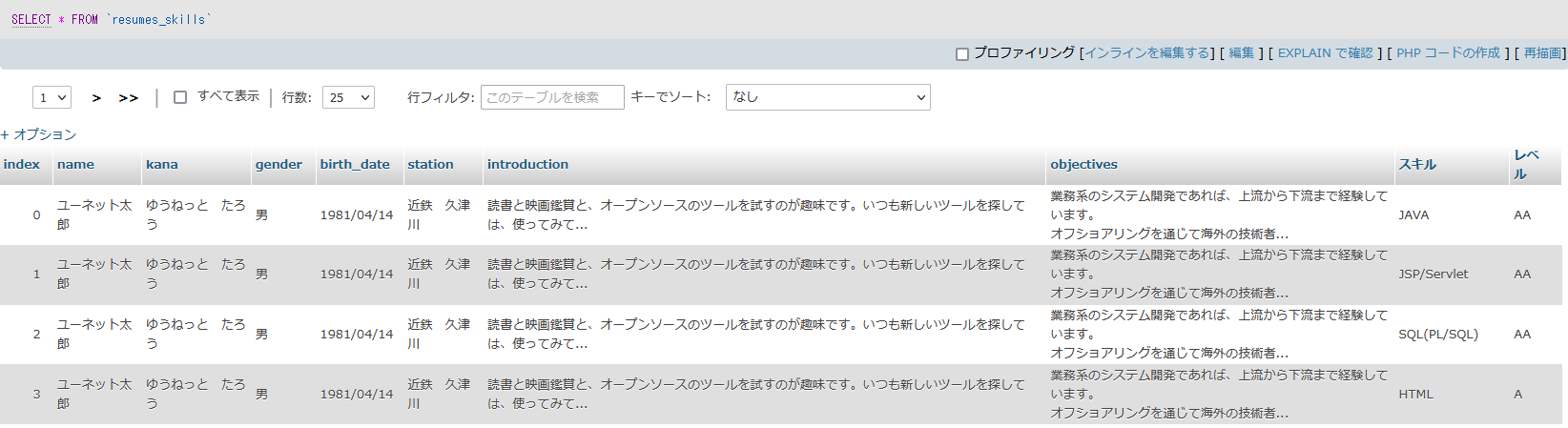
出来上がったテーブルはこのようになりました:

データも作成されています。下図はスキルテーブルの中身ですが、技術者情報が全ての行に取り込まれています。
まとめ
今回は、リレーショナルDBへデータを格納する、1回目の記事でした。
次回、最終回では、正規化を含めたリレーショナルなテーブルへの格納を検討します。