
前回の記事ではEXCELファイルをデータベースへ格納する、簡単な例を紹介しました。
表形式のデータを扱うEXCELファイルならば、前回の内容を応用すればデータベースに格納することが出来ました。
それでは、表形式のEXCEL以外の場合を今度は検討してみます。
非テーブル形式のEXCELをデータベース化する
業務経歴書というのは、IT業界では技術者を紹介するときに利用される資料です。どういう人物でどういうキャリアがあるかを簡単に説明する資料ですが、各社様々な書式があって、EXCELでの管理になっているところが少なくありません。弊社でもEXCELでの管理になってしまっています。
このEXCELファイルを、データベース化していきます。
方針
まずはECELファイルを、ドキュメントDBにJSON形式で保存するようにします。その後、RDBMSに保存することを試みます。
ここでは、ドキュメントDBには MongoDB を使います。
ドキュメントDBに保存することで、EXCELの情報を最大限度残したまま、他システムから参照出来るようにします。この段階では、厳密にRDBMSにどのような形でデータを保持するかは、考えないで、EXCELファイルに即して、出来るだけ取りこぼしの少ない形で、保存するデータ形式を考えます。
フローを図示します:
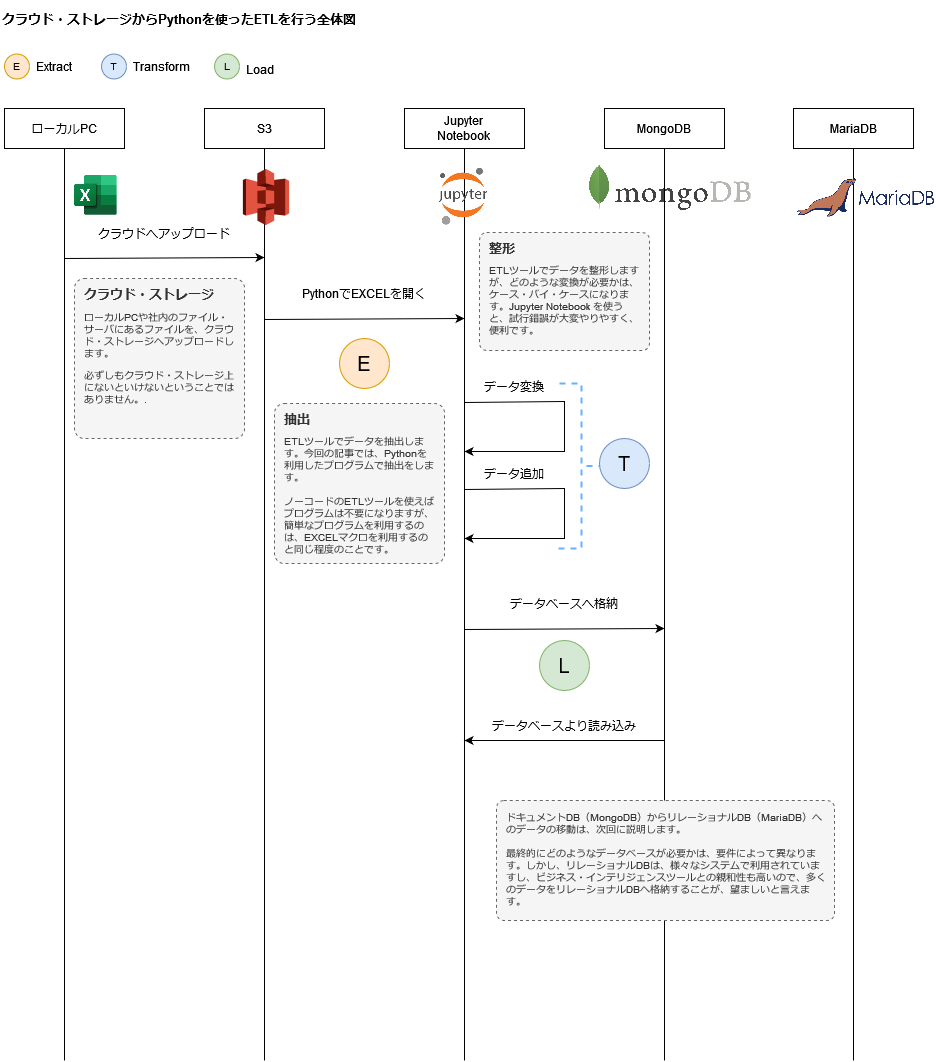
それでは、早速、EXCELファイルを開くところから始めましょう。
EXCELファイルを開く
ここは1回目の記事と同じです。
クラウドストレージ、AWSのS3に格納してあるEXCELファイルを、ETL処理を行っているサーバまでダウンロードしてきます:
import boto3
import pandas
# クラウド・ストレージ S3 への接続情報
client = boto3.client(
's3',
aws_access_key_id = '★★アクセスキーID★★',
aws_secret_access_key = '★★シークレットキー★★',
region_name = '★★リジョン★★'
)
# S3のバケットからファイルを取得し、 files フォルダの中へダウンロードする
client.download_file('minamirnd',
'test/業務経歴書(YNET太郎).xlsx',
'./files/業務経歴書(YNET太郎).xlsx')
構造を確認する
EXCELファイルはこのような形をしています:
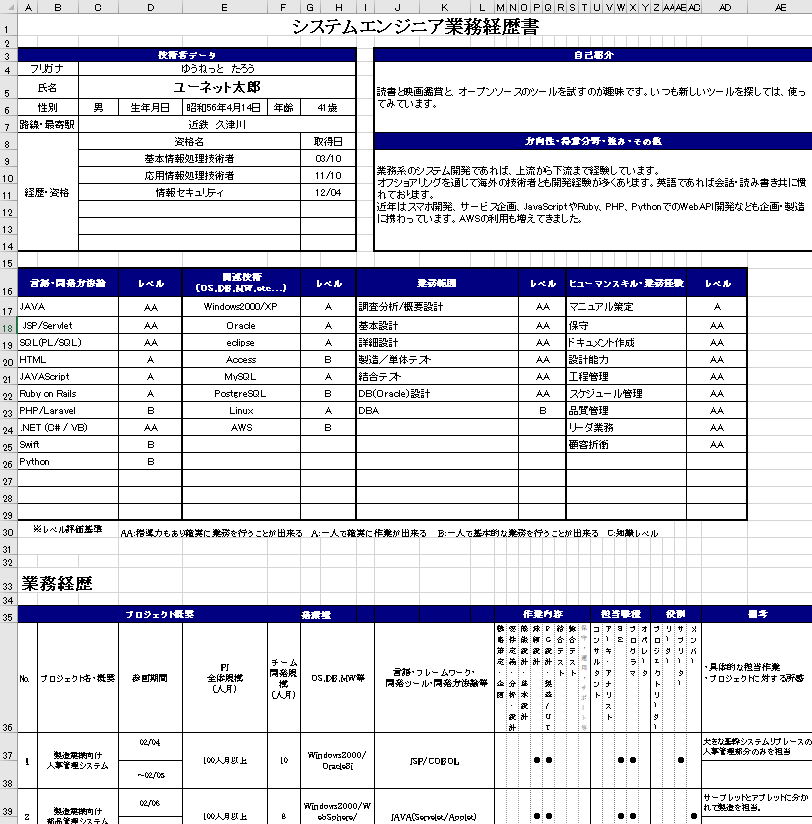
このEXCELを見ると、おおよそ以下のような構造です:
- 技術者データ
- 自己紹介
- 得意分野
- スキル・レベル
- 業務経歴
若干名称が異なりますが、細かいところにこだわる理由がなければ、簡潔にまとめるべきなので、この5つで考えます。
JSON構造を考える
従って、JSON にすると、以下のような構造になるでしょう
{
技術者データ: {
氏名: string,
よみがな: string,
生年月日: string,
性別: string,
最寄り駅: string,
資格: [
{ 名称: string, 取得日: string },
...
]
},
自己紹介: string,
得意分野: string,
スキル・レベル: [
{ スキル: string, レベル: string},
...
],
業務経歴: [
{
責任-戦略策定・企画: string ,
責任-要件定義・分析・設計: string ,
責任-機能設計・基本設計: string ,
責任-詳細設計: string ,
責任-PG設計・製造/UT: string ,
責任-結合テスト: string ,
責任-総合テスト: string ,
責任-保守・運用・サポート等: string ,
担当-コンサルタント: string ,
担当-アーキ・アナリスト: string ,
担当-SE: string ,
担当-プログラマ: string ,
担当-オペレータ: string ,
役割-プロジェクトリーダー: string ,
役割-リーダー: string ,
役割-サブリーター: string ,
役割-メンバー: string ,
備考: string
},
...
]
}以上に加えて、データ・マネジメントに有用な情報を管理するためのメタデータを加えます。
metadata: {
file_name: ファイル名,
register_datetime: 登録日時,
register_user: 登録ユーザ
}
技術者データ を取り込む
技術者データを取り込む部分を考えます。少し長くなりますが、やっていることは:
- EXCEL を開く
- 技術者情報の記載のあるセルの値を読み取る
- 資格情報の一覧を読み込む
- メタデータを加える
- 技術者情報をJSON形式にする
の5つです。
import json
import pandas as pd
from openpyxl import load_workbook
import time
from datetime import date
from datetime import datetime
# 1. EXCEL を開く
# 技術者情報はテーブル形式になっていないので、個別のセルをよんでデータを作成する
# EXCELファイルを開く
ws = load_workbook('./files/業務経歴書(YNET太郎).xlsx').active
# 2. 技術者情報の記載のあるセルの値を読み取る
kana = ws['c4'].value
name = ws['c5'].value
gender = ws['c6'].value
station = ws['c7'].value
introduction = ws['j4'].value
objectives = ws['j9'].value
# 生年月日は日付型なので、少し整形が必要でした。
# 読み込んだ値を、YYYY/MM/DD の書式に変換します
# 参考
# https://stackoverflow.com/questions/28154066/how-to-convert-datetime-to-integer-in-python
# print(datetime.fromordinal(datetime(1900, 1, 1).toordinal() + 29690 - 2))
birth_date_value = ws['e6'].value
birth_date = datetime.fromordinal(datetime(1900, 1, 1).toordinal() + birth_date_value - 2).strftime('%Y/%m/%d')
資格情報を読み込む部分は少しややこしいですが以下のようになります:
# 3. 資格情報の一覧を読み込む
# 資格情報は、表形式になっているので、まとめて読み込みます
# シートの頭の7行は飛ばして(skiprows=7)
# 読み込む列は C 列と G 列のみ (usecols = 'C, G')
# 読み込み行数はEXCELの書式より、6行(nrows = 6)
certificates = pd.read_excel('./files/業務経歴書(YNET太郎).xlsx',
skiprows = 7,
usecols = 'C,G',
nrows = 6)
# 空行は削除
certificates = certificates.dropna()
# 日付型は文字列に変更
certificates['取得日'] = certificates['取得日'].dt.strftime('%Y-%m-%d')
# Dataframe 型から Dictionary 型へ変換(JSONにするために事前準備)
certificates = certificates.to_dict(orient='records')
読み込んだ情報から、JSONを作成するための処理を追加します。
# 技術者情報を保存するJSONを作ります
engineer_json = {}
# 4.メタデータを加える
metadata = {}
metadata['register_datetime'] = str(datetime.now())
metadata['register_user'] = 'masahiro.minami'
metadata['file_name'] = '業務経歴書(YNET太郎).xlsx'
engineer_json['metadata'] = metadata
# 5. 技術者情報をJSON形式にする
engineer_json['氏名'] = name
engineer_json['よみかな'] = kana
engineer_json['性別'] = gender
engineer_json['生年月日'] = birth_date
engineer_json['最寄り駅'] = station
engineer_json['自己紹介'] = introduction
engineer_json['方向性'] = objectives
engineer_json['資格'] = certificatesその他の一覧情報も似たような処理を行いますが、少しずつ工夫をしています。
まず、スキルの部分は、4つの列に分かれていますが、全て「スキル」としてまとめて取り込みます。
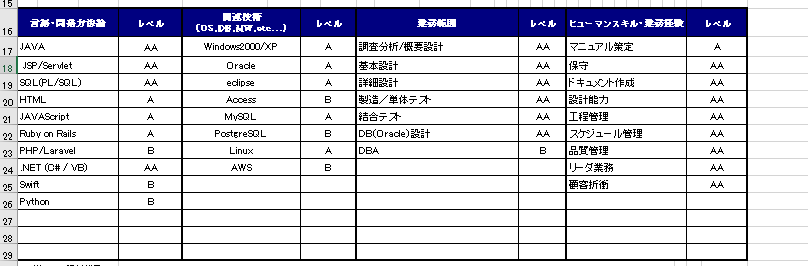
コードは以下のようになります:
# スキル
# 4列に分かれているのでそれぞれ表形式で読み込む
skill_01 = pd.read_excel('./files/業務経歴書(YNET太郎).xlsx',
skiprows = 15,
usecols = 'A,D',
nrows = 13)
skill_02 = pd.read_excel('./files/業務経歴書(YNET太郎).xlsx',
skiprows = 15,
usecols = 'E,G',
nrows = 13)
skill_03 = pd.read_excel('./files/業務経歴書(YNET太郎).xlsx',
skiprows = 15,
usecols = 'I,O',
nrows = 13)
skill_04 = pd.read_excel('./files/業務経歴書(YNET太郎).xlsx',
skiprows = 15,
usecols = 'S,AC',
nrows = 13)
# 列名を 「スキル」と「レベル」に変更する
# 全ての列名を最初の表の列名と同じにする
skill_02.columns = skill_01.columns
skill_03.columns = skill_01.columns
skill_04.columns = skill_01.columns
# 全ての表を1つにまとめる。これで1つの大きな表形式になる。
skills = pd.concat([skill_01, skill_02, skill_03, skill_04], ignore_index = True)
# 列名「言語・開発方法論」を、「スキル」とする。これで、「スキル」と「レベル」の2つの列の表形式になる
skills = skills.rename(columns = {'言語・開発方法論': 'スキル'})
# 空行は削除
skills = skills.dropna()
# Dataframe 型から Dictionary 型へ変換(JSONにするために事前準備)
skills = skills.to_dict(orient='records')
engineer_json['スキル'] = skills
業務経歴の部分は、列がたくさんあります。日付や数値項目もありますが、今回は全て文字列として扱うこととし、単純化します。
# 業務経歴
# 全体を取り込む。データ型の変換で手間取らないために、ここでは全てを「文字列」として取り込む(dtype=str)
experiences = pd.read_excel('./files/業務経歴書(YNET太郎).xlsx',
skiprows = 35,
usecols = 'A,B,D:G,J,M:AD',
nrows = 200,
dtype=str)
# № 列が NaN の行は削除
experiences = experiences.dropna(subset=['№'])
# カラム名に改行が入っていたり、長すぎるものを整理する
experiences = experiences.rename(columns={'№':'NO'})
experiences = experiences.rename(columns={'PJ\n全体規模\n(人月)':'PJ全体規模(人月)'})
experiences = experiences.rename(columns={'チーム\n開発規模\n(人月)':'チーム開発規模'})
experiences = experiences.rename(columns={'言語・フレームワーク・\n 開発ツール・開発方法論等':'言語・フレームワーク・開発ツール'})
experiences = experiences.rename(columns={'・具体的な担当作業\n・プロジェクトに対する所感\n':'備考'})
experiences = experiences.to_dict(orient='records')
# JSONに値を設定する
engineer_json['業務経歴'] = experiences
ドキュメントDBへ格納する
技術者情報を一つのJSON形式にまとめたので、そのままドキュメントDB(MongoDB)へ格納します。
表形式ではない情報の中に、表形式の情報を複数まとめた形で JSON は表現出来ますが、それをそのままデータベースに格納出来るのが、ドキュメントDBの面白いところです。
ETLの観点から考えると、まとめたい情報を一度まとめて、そのまま保存しておくことが出来るのが、便利なところです。リレーショナル・データベースでは、一人のエンジニアの情報を、1つのテーブルで表現しようとすると、無理があります。
MongoDB へ格納するところはいたって単純です:
# MongoDB へ接続
from pymongo import MongoClient
import pymongo
# 接続文字列
CONNECTION_STRING = "mongodb://★★mongoDBのURL★★/?ssl=true"
# Create a connection using MongoClient. You can import MongoClient or use pymongo.MongoClient
from pymongo import MongoClient
client = MongoClient(CONNECTION_STRING)
# データベースへ格納する
# MongoDB では、「データベース」の中に「コレクション」というものがあり、「コレクション」の中にドキュメントを格納します。
# ここでは、「testdb」というデータベースを作成し、その中に「resumes」というコレクションを作成します。
# resumes コレクションの中に、経歴書を格納していきます
database = client['testdb']
collection = database['resumes']
# 格納する
doc_id = collection.insert_one(engineer_json)格納後のデータを参照してみます。testdb -> resumes -> の中に、データが格納されているのが分かります。
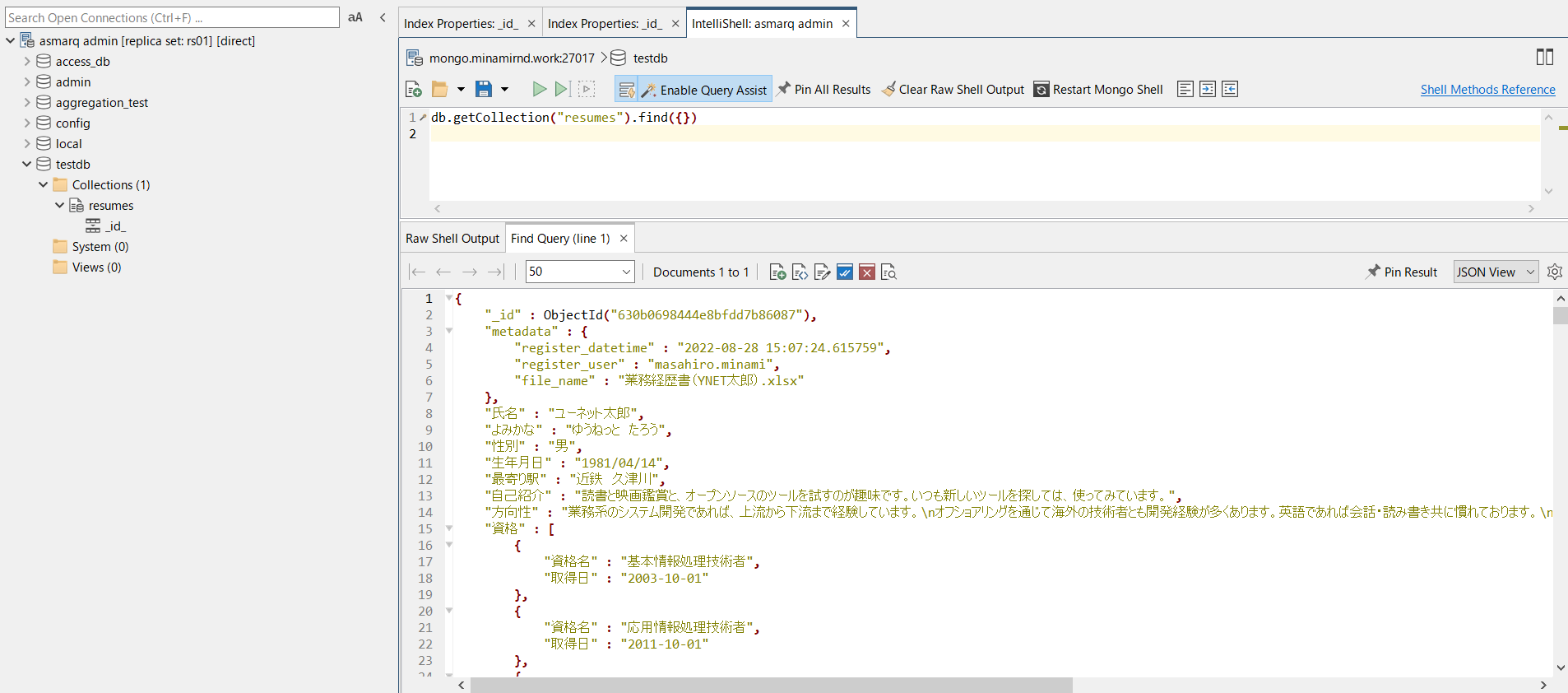
ドキュメントDBで検索を行う
ドキュメントDBでは、格納されるJSONは、ネストした構造になっていますが、このように検索が出来ます:
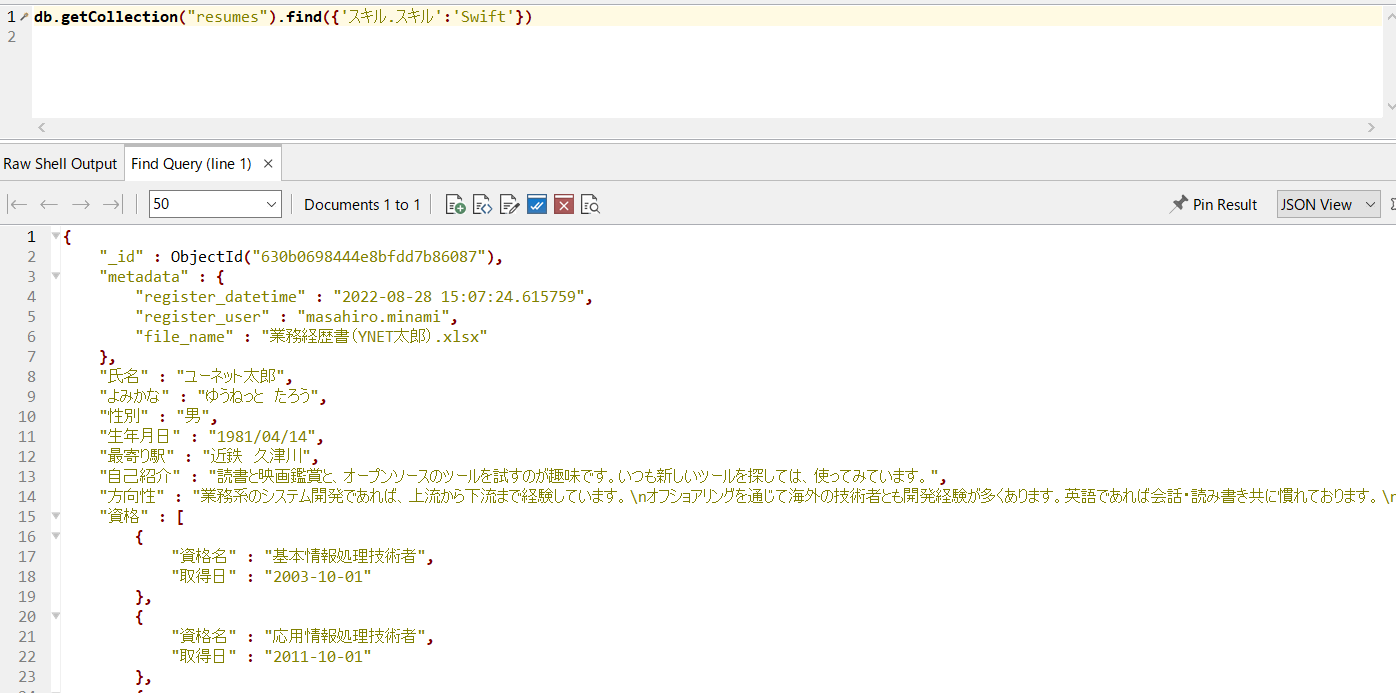
collection.find({'スキル.スキル':'Swift'})
これは、
コレクションの中で、「スキル」という属性の下の「スキル」という項目に、’Swift’という文字列が含まれているドキュメントを検索する
という意味になります。
現在は1レコードしかないので、結果は当然1件見つかります。
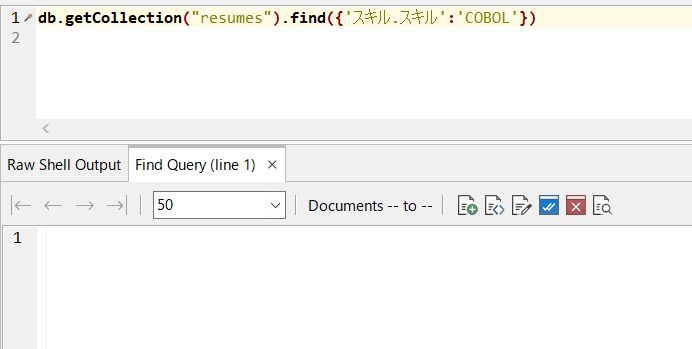
しかし、ユーネット太郎の経歴書にないスキルとして、例えば「COBOL」で検索をすると、見つかりません:
まとめ
今回はコード量が多くなってしまいましたが、EXCELファイルのデータを、柔軟に、JSON形式に取り込むことで、1つのデータとしてドキュメントDBへ格納出来ることがご理解いただけたのではないでしょうか。
こうしてデータベース化出来ると、EXCELの中にあっただけではなかなか再利用が出来なかったデータでも、様々な分析に利用することを検討出来ます。
次の記事では、ドキュメントDBに格納したデータを、リレーショナルDBへ格納することを検討してみます。同じデータベースと言っても、ドキュメントDBとリレーショナル
得意分野が異なりますので、何を目的とするかによって、使い分けることになります。