
何回かにわたってEXCELデータをデータベースに入れる紹介を行います。
1回目は、簡単な例として、EXCELファイルにテーブルが1つあり、それをデータベースに入れる、という例です。
利用するツールについて
このシリーズ記事では以下のツールやシステムを使います
- Python と Jupyter Notebook
- MongoDB
- MariaDB
- AWS S3
- n8n
それぞれの用意の仕方は触れませんので、お問合せ頂ければと思います。
処理の流れ
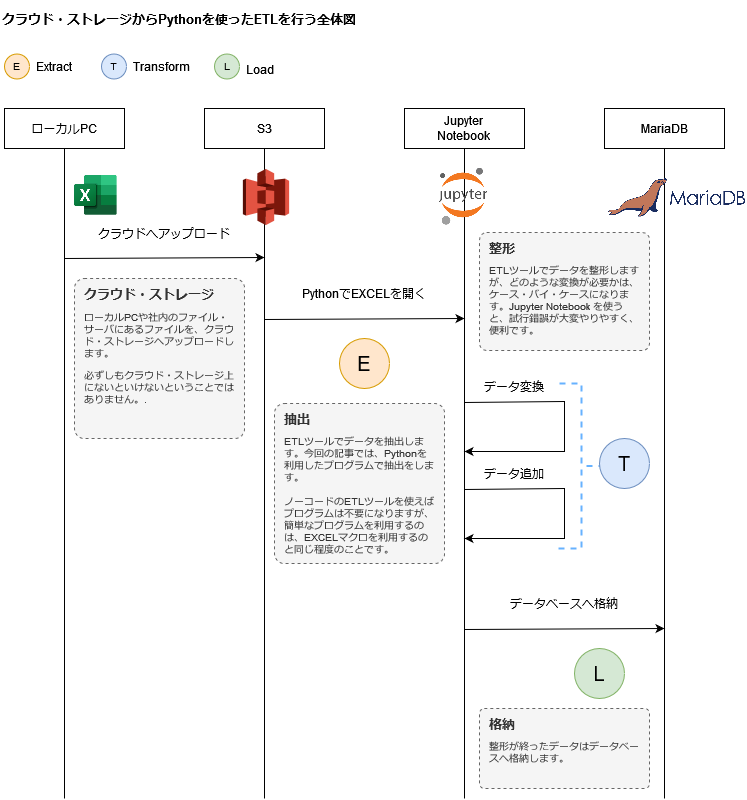
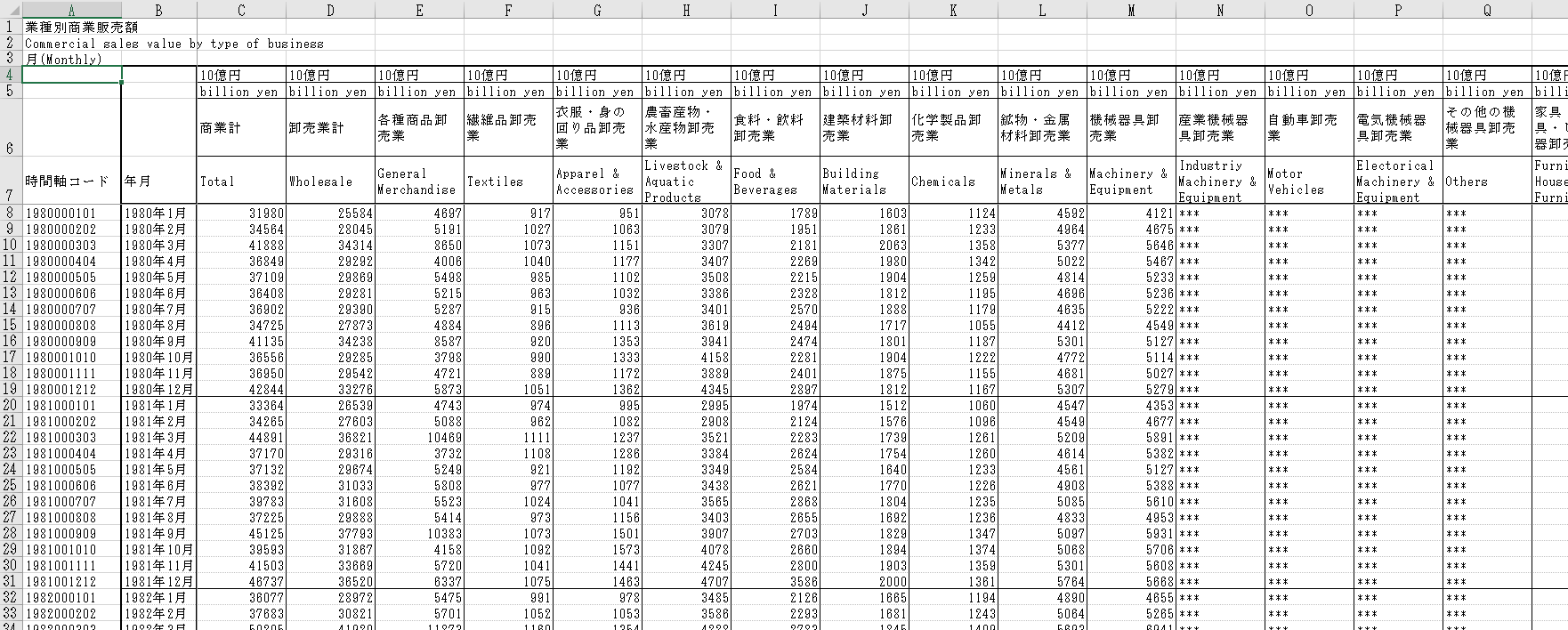
対象とするEXCELファイルは、経産省の統計データで、このようになっていました:
PythonによるETL
では、経産省にある統計データのEXCELファイルを、MariaDB へ入れるまでの Extract, Transform, Load を見てみます。
ファイルはS3上にアップロードしてある前提です。

S3からEXCELファイルを持ってきて、Jupyter Notebook の動くサーバにダウンロードします。
import boto3
import pandas
# クラウド・ストレージ S3 への接続情報。適切な値に変更してください。
client = boto3.client(
's3',
aws_access_key_id = '★★★★アクセスキー★★★★',
aws_secret_access_key = '★★★★シークレットキー★★★★',
region_name = '★★★★リジョン★★★★'
)
# S3のバケットからファイルを取得し、 files フォルダの中へダウンロードする
client.download_file('minamirnd',
'marketing/meti_timeseries_Commercial_sales_value_by_type_of_business_h2slt11j.xls',
'./files/meti_timeseries_Commercial_sales_value_by_type_of_business.xls')
実行すると、エラーがなければ、 files の下にダウンロードされた meti_timeseries_Commercial_sales_value_by_type_of_business.xls が出来ます。
次にファイルを読み込みます。Extractの処理になります。
import pandas as pd
# 対象とするのはシート「販売額(value)(月次M)」
df = pd.read_excel('files/meti_timeseries_Commercial_sales_value_by_type_of_business.xls',
sheet_name ='販売額(value)(月次M)',
header = 6 )
# 数値項目に *** という文字列が入っている部分がある
df.head一部のカラムに *** という文字列が入っていることが確認出来ます:
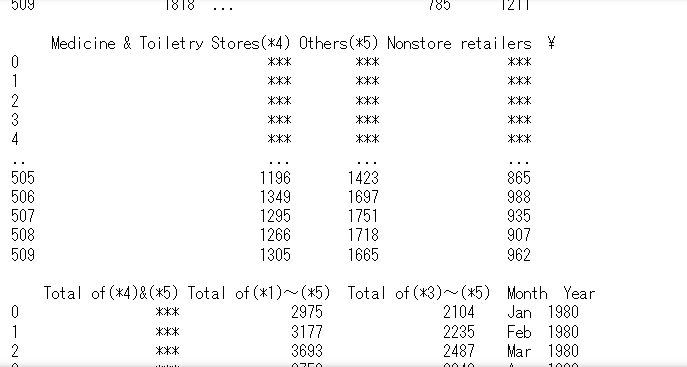
EXCELを見ると、確かに *** という値を入れてあります。統計が無かった時期を表しています。
# *** という文字列を含むカラムをEXCELで確認しておく。
# Industriy Machinery & Equipment
# Motor Vehicles
# Electorical Machinery & Equipment Others
# Fuel(*3) Medicine & Toiletry Stores(*4)
# Others(*5)
# Nonstore retailers
# Total of(*4)&(*5)
# Total of(*1)~(*5)
# Total of(*3)~(*5)
cols_to_convert = [
'Industriy Machinery & Equipment',
'Motor Vehicles',
'Electorical Machinery & Equipment',
'Others',
'Fuel(*3)',
'Medicine & Toiletry Stores(*4)',
'Others(*5)',
'Nonstore retailers',
'Total of(*4)&(*5)',
'Total of(*1)~(*5)',
'Total of(*3)~(*5)'
]
# 指定したカラムを「数値変換」し、既存の値を上書きする
df[cols_to_convert] = df[cols_to_convert].apply(pd.to_numeric, errors='coerce', axis=1)
# 変換後、NaN が入っていることを確認する
df[cols_to_convert].head実行すると、文字列を数値項目に変更した結果、 NaN に変わっています
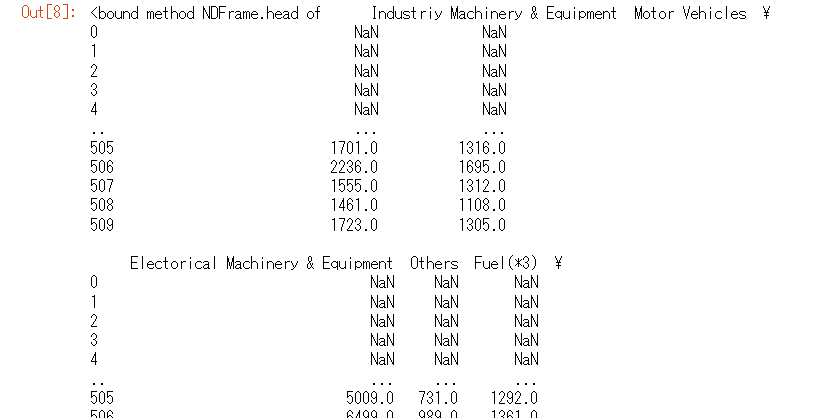
後は、追加の情報をデータフレームに追加します
# 追加情報を加える
df['source'] = 'METI'
df['data_name'] = '業種別商業販売額'
df['url'] = 'https://www.meti.go.jp/statistics/tyo/syoudou/result-2/excel/h2slt11j.xls'
最後に、Pythonのデータフレームをデータベースへ格納します。
import pandas as pd
from sqlalchemy import create_engine
# データベースへの接続情報
hostname="192.168.10.3"
dbname="marketingdb"
uname="marketing"
pwd="8~kT.5vc189Y7+cV"
# 接続文字列を組み立てる。.format を使って、プレースホルダの変数へ値を代入している
engine = create_engine("mysql+pymysql://{user}:{pw}@{host}/{db}".format(host=hostname, db=dbname, user=uname, pw=pwd))
# テーブル名を指定して、SQLを発行する
# 既存のテーブルならば追加でINSERTをする
# テーブルが存在しなければ、新しくテーブルを作成する(if_exists='append')
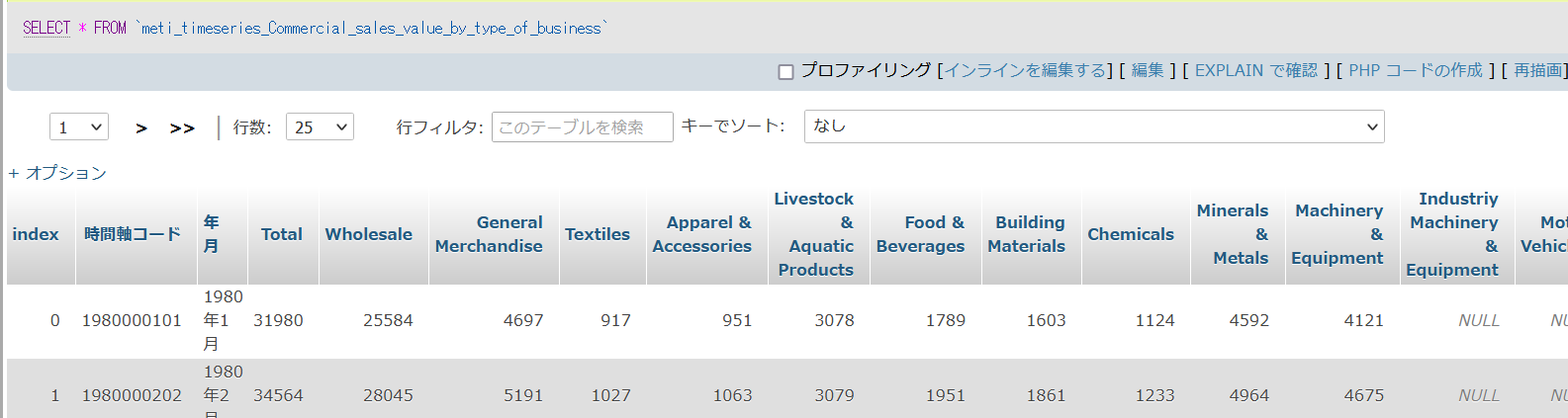
df.to_sql('meti_timeseries_Commercial_sales_value_by_type_of_business', engine, index=True, if_exists='append')
データベースを確認してみます:
この記事でのまとめ
Pythonを使った簡単な ETL について紹介しました。
プログラムを組まないといけないのと、この環境を用意しないといけない点は、EXCEL VBA に比べて煩雑ですが、EXCELのデータをデータベースに格納するまで、ツールを用意するだけで出来ます。
数値でない項目を排除したり、未だないテーブルを新規で作成するのは、実際には面倒な処理ですが、数行のコードで実現出来ています。VBAで書こうとすれば、結構な量のコードが必要になるでしょう。この辺りは、Pythonの強みを利用した処理になります。データの重要性が高まる中、Pythonは非常に便利なプログラミング言語と言えます。
この記事で対象としたEXCELファイルは、それでも、1つの表形式のデータを持っているだけでした。
次回は、もう少し複雑な書式のEXCELの場合に、どうやってデータベースにまでもっていけるかを検討したいと思います。
データ・プラットフォームのご相談は弊社まで
弊社ではお客様にあったデータ・プラットフォームを企画・構築いたします。既存のツールでのデータ・プラットフォームがうまく行かない場合、一度ご相談下さい。
Photo by Mika Baumeister on Unsplash